CMU-15-445笔记(五)
B+ Tree
B+树是一个自平衡的树结构,查找,插入,删除都是O(log n),B+是是一个M-way的搜索树
- 所有叶子结点的深度都是一样的
- 所有结点(除了root),都是至少半满的
- M/2 <= keys <= M-1
- 所有内部结点都有k个keys以及k+1个非空子节点
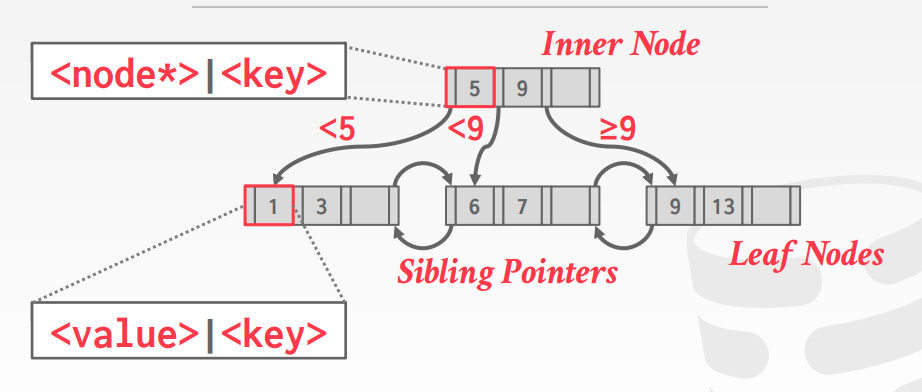
节点
叶子节点
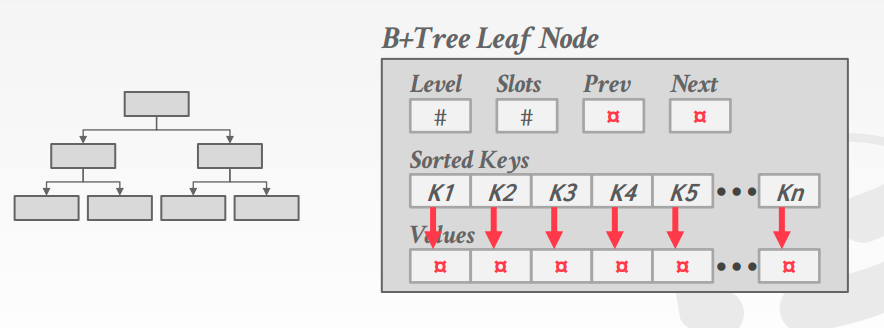
叶子节点内部存储类似page的存储,头部为元信息,然后存储key,最后存储value,key提供对应value的偏移值。
叶子节点中存储value的方式主要有两种
- Record Ids
存储record id,指向数据存放的位置 - Tuple Data
直接将数据存放在leaf node中
B Tree和B+ Tree的区别
B Tree中内部节点会存储value,但是B+ Tree中 value只会存在leaf node 中,所以B Tree中不会出现相同的key,但是B+ Tree中会。
Insert
- 首先找到要插入的叶子节点L
- 将数据按顺序放到L中
- 如果L空间足够,就完成插入了
- 如果不够,分裂L,成为L和L2,同时要在父节点上增加entry,如果父节点不够,就递归分裂
Delete
- 首先找到目标所在的叶子节点L,删除该数的entry
- 如果L至少半满,那么操作结束,如果少于半满,那么尝试从兄弟节点拆借entries,如果失败,那么就尝试与兄弟节点合并
- 如果与兄弟节点合并,那么递归的删除父节点的
L的entry
Clustered Indexes 聚簇索引
聚簇索引是将主键按照顺序排序存储,每个table只能还有一个聚簇索引,如果table中没有主键,那么就设置一列隐藏列作为主键
Selection Conditions
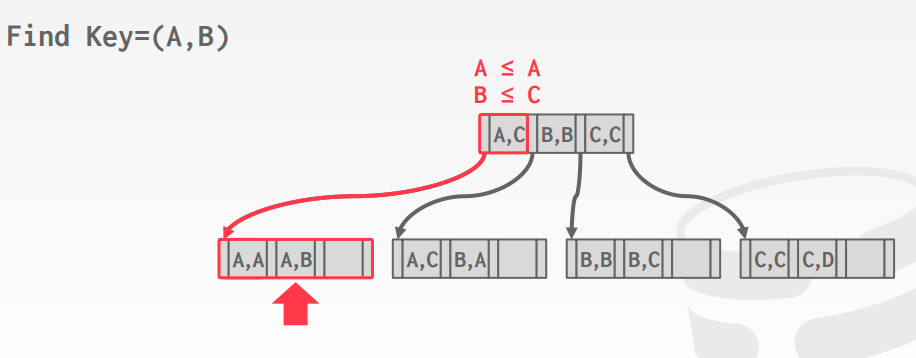
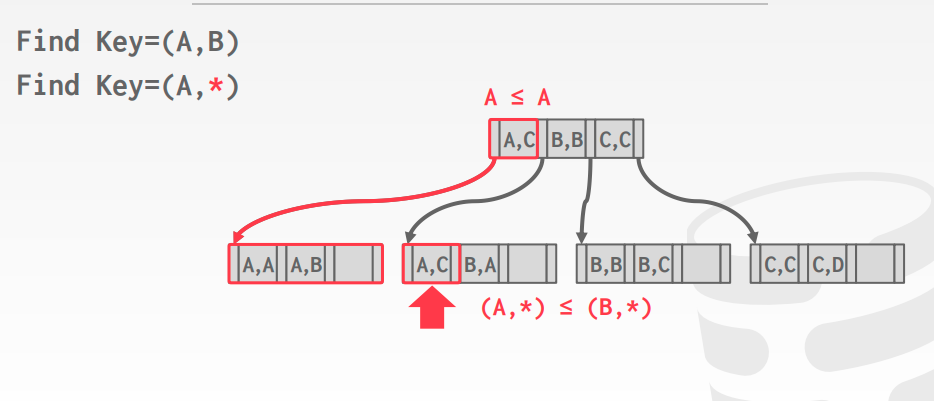
B+树支持多种的搜索方式,以<A, B, C>为例
- (a = 5 AND b = 3)
- (b = 3)
B+ Tree Design Choices
Node Size
存储设备越小,Node Size应该越大
- HDD 1MB
- SSD 10KB
- In-Memory 512B
Merge Threshold
可以延迟Merge操作,因为Merge操作开销过大
Variable Length Keys
应对变长变量的方式
- 存储指针
- 现在已经不使用这种方法了
- 可变长度的节点
- 每个节点的大小可以改变,但是需要注意内存管理
- 这种方式也没人使用
- Padding
- 固定一个最大大小的尺寸,存储后的数据小于这个尺寸,那么就填充空值
- Key Map / Indirection
- 设立一个Key Map,用来指向key value的位置

Non-Unique Indexes
使用索引的key可能是不唯一的,通常有两种方式
- Duplicate Key
- 多次存储相同的key
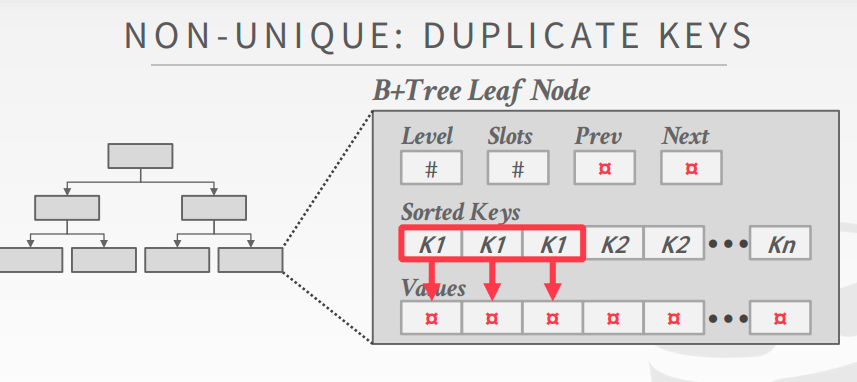
- Value list
- Key只出现一次,但是需要维护一个key链表,表示在这个key下的value
-
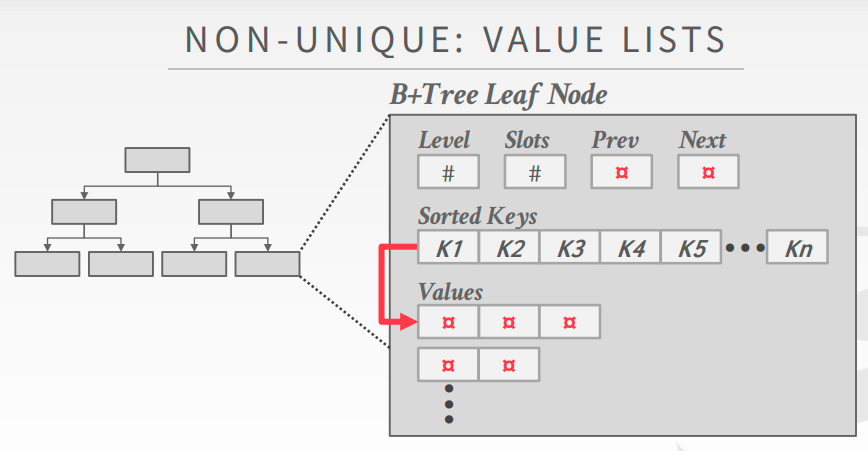
Intra-Node Search
查找内部节点的方法:
- Linear
- 线性查找
- Binary
- 二分查找
- Interpolation
- 如果提前知道key的样子/属性/分布,可以用数学的方式来近似的查找位置
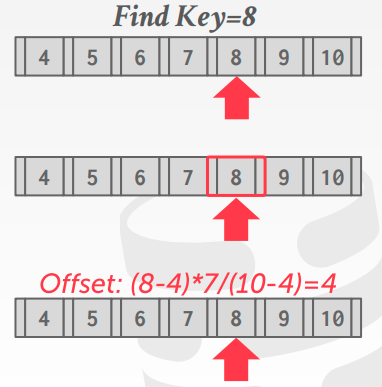
- 如果提前知道key的样子/属性/分布,可以用数学的方式来近似的查找位置
Optimizations
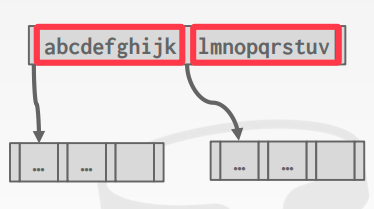
Prefix Compression
如果存储在同一个叶子节点的keys 有相同的前缀,可以先将相同的前缀存储起来,然后存key的时候就不用存前缀了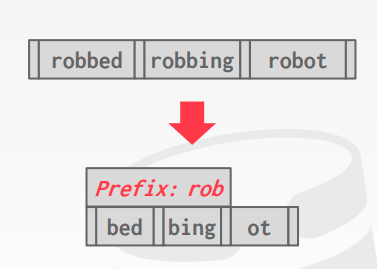
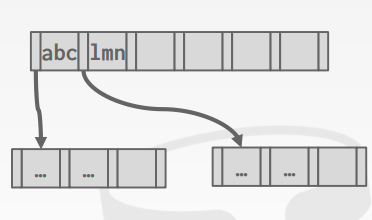
Suffix Truncation
在内部节点的key只用于查找子节点的位置,所以可以只存储足够的prefix就要可以达到这样的目的。
Bulk Insert
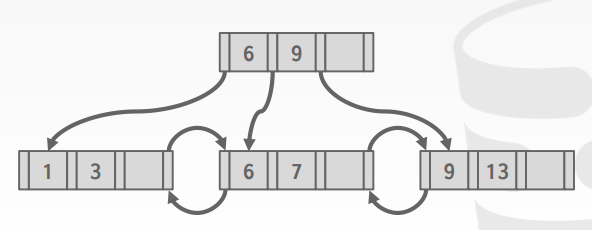
如果提前有了所有的keys,那么可以排序,排完序之后从下往上建树,这是最快的建树方式
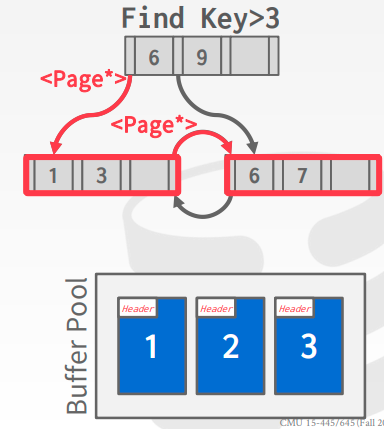
Pointer Swizzling
Node使用page id来存储对其他node的引用,所以DBMS需要每次都从buffer pool中获取对应的page,所以如果一个page已经pinned了,可以直接存储这个page的指针,避免再次去buffer pool 中获取page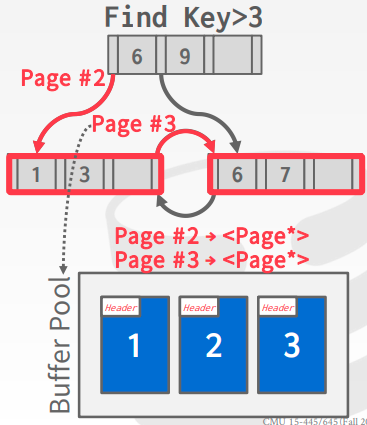
CMU-15-445笔记(五)